SQL View Matching Across Systems
TECHNOLOGY
Ann Yiming Yang
3/16/20264 min read


View matching is the optimizer’s ability to rewrite a query so that it uses a materialized view (MV) instead of scanning base tables.
Instead of: query → scan raw tables → compute result; the optimizer can do: query → rewrite → scan precomputed materialized view → compute result
The core challenge is proving that the materialized view contains enough information to answer the query correctly. The optimizer must reason about:
rows contained in the view
columns available
join structure
aggregation level
filters and predicates
freshness
Once it proves correctness, the optimizer still decides whether using the view is cheaper than scanning base tables.
Different systems implement this differently, one of the key practical difference across engines is which types of queries they allow to match materialized views.
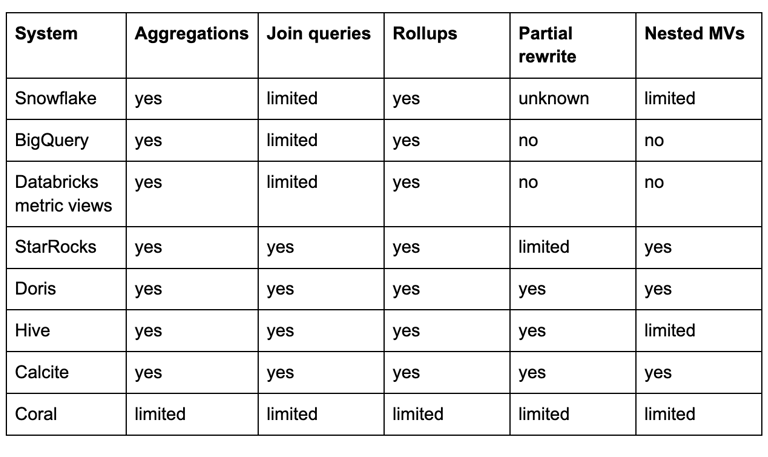
Major systems
Snowflake
Snowflake supports automatic query rewrite using materialized views. The optimizer may transparently replace parts of a query plan with reads from a materialized view.
Supported query patterns
Aggregation queries
query:
SELECT product_id, SUM(revenue) FROM sales GROUP BY product_id;
MV:
SELECT product_id, SUM(revenue) FROM sales GROUP BY product_id;
The optimizer can directly substitute the MV.
Rollup aggregation
A finer-grained MV can answer a coarser query.
query:
SELECT product_id, SUM(revenue) FROM sales GROUP BY product_id;
MV:
SELECT date, product_id, SUM(revenue) FROM sales GROUP BY date, product_id;
The optimizer aggregates the MV again.
Filtered aggregations
Queries that filter rows can still match if the MV contains all rows.
SELECT product_id, SUM(revenue) FROM sales WHERE date >= '2026-01-01' GROUP BY product_id;
Join queries (limited)
Snowflake can match joins when the MV already includes the join.
Typical example: sales JOIN products if the MV precomputes that join.
Limitation
Snowflake does not publish exact boundaries, but common limitations include:
outer joins
window functions
complex nested subqueries
non-deterministic expressions
BigQuery
BigQuery provides one of the clearest descriptions of MV rewrite behavior. It calls the feature smart tuning,
which automatically rewrites queries to use materialized views when possible.
Supported query shapes
Aggregation queries
SELECT k, SUM(x) FROM table GROUP BY k;
Filtered aggregations
SELECT k, SUM(x) FROM table WHERE date >= '2026-01-01' GROUP BY k;
Rollup queries
MV grouping is finer than the query grouping.
MV example: GROUP BY date, product
Query example: GROUP BY product
Limitations
BigQuery explicitly excludes certain patterns from rewrite:
LEFT OUTER JOIN
UNION ALL
queries referencing logical views
non-incremental materialized views
CDC-enabled base tables
These restrictions effectively mean BigQuery primarily supports SPJG queries (select-project-join-group-by).
Databricks
Databricks has two distinct stories. Ordinary SQL materialized views
For regular materialized views the documentation focuses mainly on:
creation
refresh
pipeline-backed maintenance
Transparent rewrite from base-table queries is less clearly documented.
Metric view materialization
Metric views explicitly support view matching. Two strategies are described:
Exact match: the query exactly matches a materialization.
Aggregate-aware matching: the optimizer can roll up a more granular materialization.
Typical limitations
Metric views mainly focus on aggregation workloads and generally do not support:
arbitrary joins
complex relational rewrites
deeply nested queries
StarRocks
StarRocks provides a strong open-source implementation of MV rewrite.
The documentation describes rewriting over SPJG queries (select-project-join-group-by).
Supported query patterns
Aggregations
SELECT k, SUM(x) FROM table GROUP BY k;
Join + aggregation
SELECT p.category, SUM(s.revenue) FROM sales s JOIN product p ON s.pid = p.pid GROUP BY p.category;
If the MV precomputes the join.
Nested materialized views are also supported, and StarRocks supports rewrite for approximate distinct aggregates using bitmap or HLL techniques.
Limitations
Typical limitations include:
outer joins
window functions
complex correlated subqueries
Apache Doris
Doris explicitly describes rewrite using SPJG queries.
Supported query patterns
Aggregation queries with GROUP BY
Join queries such as fact JOIN dimension
Rollups when MV grouping is finer than the query grouping.
Additional capabilities documented include:
condition compensation
nested materialized views
partial rewrites
multi-dimensional aggregations
Hive (via Calcite)
Hive supports MV rewrite through Apache Calcite. Calcite handles the logical rewrite while Hive manages lifecycle and freshness.
Supported query patterns
SPJ queries (select-project-join)
SPJG queries (select-project-join-group-by)
Aggregate rollups
Partial rewrites combining view results with base-table results.
Limitations
window functions
correlated subqueries
some outer join patterns
Apache Calcite
Calcite is the clearest reference implementation for view matching algorithms.
Supported query patterns
Join + filter + project chains
Aggregation queries with GROUP BY
Aggregate rollups
Partial rewrites using UNION between the view and base tables.
Calcite can also use schema constraints such as primary keys, foreign keys, and uniqueness constraints to prove equivalence.
Coral
Coral is fundamentally different. It focuses on:
view expansion
SQL translation
semantic rewriting
rather than a full MV rewrite engine.
Typical use cases include:
translating Hive views to Trino
expanding nested views
normalizing SQL across engines
Materialized-view rewrite support is currently limited compared to Calcite.
Common patterns across systems
Despite architectural differences most systems match similar query families.
Aggregation queries
GROUP BY queries with SUM, COUNT, MIN, MAX.
Rollup aggregation
A finer-grained MV answering a coarser query.
Example:
MV: GROUP BY date, product
Query: GROUP BY product
Join-based summaries
If the materialized view already contains the join between fact and dimension tables the query can reuse the precomputed result.
Filter compensation
If the view contains more rows than needed the optimizer applies residual filters.
Major differences between systems
The biggest differences appear in query complexity support.
Aggregation-focused systems primarily match GROUP BY workloads.
Examples:
BigQuery
Databricks metric views
Full relational rewrite systems primary support join + filter + project + group-by queries.
Examples:
StarRocks
Doris
Calcite
Hive
Middleware rewrite systems focus more on view expansion and SQL normalization across engines.
Example:
Coral
Final takeaway
Most systems converge on supporting the same core query family:
SPJG queries (select-project-join-group-by) with aggregation rollups.
However they diverge in how far they push beyond that.
BigQuery and Databricks focus on aggregation acceleration.
StarRocks and Doris aim for full relational rewrite.
Hive and Calcite emphasize framework-driven optimization.
Coral emphasizes platform-level query rewriting.